
【導(dǎo)讀】“算力墻”“內(nèi)存墻”“功耗墻”已成為制約智能終端實(shí)現(xiàn)更復(fù)雜AI任務(wù)與更高計(jì)算效率的核心問(wèn)題。神經(jīng)網(wǎng)絡(luò)處理器(NPU)作為支撐AI計(jì)算的核心硬件單元,是突破上述技術(shù)困局的關(guān)鍵支撐。安謀科技(Arm China)推出的“周易”X3 NPU IP,通過(guò)前瞻性的架構(gòu)創(chuàng)新、深度的軟硬件協(xié)同優(yōu)化及開(kāi)放的生態(tài)構(gòu)建,為破解端側(cè)AI三大技術(shù)壁壘提供了系統(tǒng)性的技術(shù)支撐方案。該方案從算力供給的靈活適配、內(nèi)存利用效率的極致提升,到能效平衡的精準(zhǔn)調(diào)控,以全方位的技術(shù)突破,為端側(cè)AI的規(guī)模化落地提供了強(qiáng)勁動(dòng)能。

錦囊一:應(yīng)對(duì)“算力墻”,從“定點(diǎn)”到“浮點(diǎn)”,架構(gòu)升級(jí)與算力靈活配置
端側(cè)AI從CNN向Transformer遷移,對(duì)高精度浮點(diǎn)運(yùn)算的需求激增。傳統(tǒng)NPU受限于架構(gòu)適配性差、算力調(diào)度效率低等,難以滿足復(fù)雜AI場(chǎng)景的動(dòng)態(tài)需求。為應(yīng)對(duì)大模型對(duì)端側(cè)算力的嚴(yán)苛需求,“周易”X3提供了高效的解決方案。
“周易”X3的破局之道在于底層架構(gòu)革新,它采用專為大模型而生的DSP+DSA全新架構(gòu),實(shí)現(xiàn)從定點(diǎn)轉(zhuǎn)向浮點(diǎn)計(jì)算,兼顧C(jī)NN與Transformer,解決了傳統(tǒng)NPU“偏科”問(wèn)題。單Cluster可提供8-80 FP8 TFLOPS的靈活算力配置,能精準(zhǔn)匹配不同場(chǎng)景的多樣化算力需求。相較上一代產(chǎn)品,“周易”X3實(shí)現(xiàn)性能升級(jí)——AIGC大模型能力提升10倍、CNN模型性能提升30%-50%,充分釋放大模型算力潛能。
錦囊二:應(yīng)對(duì)“內(nèi)存墻”——高帶寬與智能存儲(chǔ),提升內(nèi)存利用效率
大模型參數(shù)規(guī)模龐大,內(nèi)存帶寬與存儲(chǔ)壓力是另一大瓶頸。若無(wú)法高效處理數(shù)據(jù)讀寫(xiě)與存儲(chǔ),將導(dǎo)致AI任務(wù)卡頓與響應(yīng)延遲。“周易”X3通過(guò)多重技術(shù)升級(jí)應(yīng)對(duì)內(nèi)存挑戰(zhàn):
超高速數(shù)據(jù)通道:?jiǎn)蜟ore帶寬高達(dá)256GB/s,能快速完成海量數(shù)據(jù)的讀寫(xiě),減少數(shù)據(jù)在內(nèi)存中的滯留時(shí)間。計(jì)算核心帶寬相較上一代提升4倍,可保障數(shù)據(jù)高效傳輸;
智能存儲(chǔ)架構(gòu):升級(jí)的L2 Memory存儲(chǔ)系統(tǒng)有效減少DDR訪存,提升數(shù)據(jù)吞吐效率;
硬件解壓引擎:集成自研解壓硬件WDC,使大模型Weight軟件無(wú)損壓縮后通過(guò)硬件解壓能額外獲得約15%的等效帶寬;
低精度加速模式:支持端側(cè)大模型運(yùn)行必備的W4A8/W4A16計(jì)算加速模式,兼顧存儲(chǔ)容量、帶寬與精度需求,在保證模型效果的前提下顯著提升計(jì)算效率。
實(shí)測(cè)數(shù)據(jù)顯示,多核算力線性度達(dá)70-80%、大模型Prefill階段利用率可達(dá)72%、Decode階段有效帶寬利用率突破100%[1],充分驗(yàn)證其內(nèi)存調(diào)度能力與系統(tǒng)協(xié)同優(yōu)化的卓越表現(xiàn)。
錦囊三:應(yīng)對(duì)“功耗墻”:極簡(jiǎn)調(diào)度與按需供給,實(shí)現(xiàn)能效優(yōu)化
終端設(shè)備在有限電池容量和散熱條件下,亟需通過(guò)算力與能效的協(xié)同優(yōu)化,實(shí)現(xiàn)高性能AI任務(wù)與長(zhǎng)續(xù)航的平衡。
“周易”X3集成AI專屬硬件引擎AIFF,搭配專用硬化調(diào)度器,能將CPU負(fù)載降至0.5%以下,且調(diào)度延遲極低。NPU在并行處理多項(xiàng)AI任務(wù)時(shí),無(wú)需依賴CPU頻繁介入調(diào)度,顯著降低CPU與NPU間的通信開(kāi)銷,從而降低系統(tǒng)功耗、有效延長(zhǎng)設(shè)備續(xù)航時(shí)間。
此外,“周易”X3采用可擴(kuò)展的多核架構(gòu)及層次化的內(nèi)存互連架構(gòu),支持算力靈活裁剪和擴(kuò)展,系統(tǒng)可根據(jù)AI任務(wù)復(fù)雜度實(shí)現(xiàn)“按需供能”,有效降低無(wú)效計(jì)算與數(shù)據(jù)搬移,實(shí)現(xiàn)能源利用效率最大化。
Compass AI軟件平臺(tái) 助力全鏈路高效開(kāi)發(fā)與部署
應(yīng)對(duì)端側(cè)AI“三堵墻”挑戰(zhàn),離不開(kāi)軟硬件的深度協(xié)同。“周易”X3配套的Compass AI軟件平臺(tái)憑借完善易用、開(kāi)放生態(tài)、安全保障等多維優(yōu)勢(shì),成為面對(duì)端側(cè)AI“三堵墻”困境的超強(qiáng)“金牌輔助”。
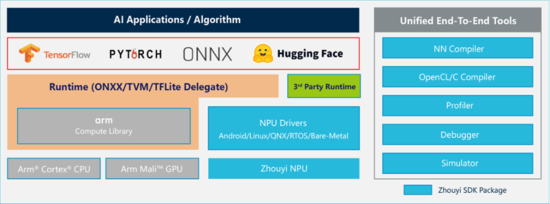
“周易” NPU Compass AI軟件平臺(tái)
Compass AI軟件平臺(tái)提供端到端統(tǒng)一工具鏈,可實(shí)現(xiàn)“一鍵部署,開(kāi)箱即用”。原生支持Hugging Face、主流AI框架與OS,支持160+算子與270+模型,并對(duì)LLM/VLM/VLA及MoE等大模型推理進(jìn)行深度優(yōu)化,實(shí)現(xiàn)從CNN到Transformer模型的無(wú)縫接入,大幅降低模型部署門(mén)檻與成本。同時(shí),平臺(tái)對(duì)量化算法的支持與具備的動(dòng)態(tài)Shape能力,可在提升性能的同時(shí)有效降低功耗,避免無(wú)效計(jì)算。
此外,Compass AI軟件平臺(tái)提供多種軟件工具,并開(kāi)放IR規(guī)格、開(kāi)源量化工具等核心組件。開(kāi)發(fā)者基于DSL編程語(yǔ)言,通過(guò)豐富的NN編譯器插件實(shí)現(xiàn)自定義算子,配合可視化調(diào)試工具,能夠?qū)崿F(xiàn)全鏈路可觀測(cè)、可優(yōu)化,極大提升不同場(chǎng)景下的開(kāi)發(fā)效率,為端側(cè)AI的算力調(diào)度、功耗控制提供底層軟件支撐。
以自研IP產(chǎn)品矩陣 助推端側(cè)AI規(guī)模化落地
在安謀科技“AI Arm CHINA”戰(zhàn)略指引下,公司將以AI為核心、Arm?生態(tài)為支撐、本土創(chuàng)新為根基,持續(xù)推進(jìn)“周易”NPU、“星辰”CPU、“山海”SPU和“玲瓏”多媒體處理器四大自研IP產(chǎn)品的研發(fā),與產(chǎn)業(yè)伙伴協(xié)同共建中國(guó)智能計(jì)算生態(tài),助推端側(cè)AI的規(guī)模化落地。
“周易”X3 NPU IP以架構(gòu)革新、內(nèi)存優(yōu)化、智能調(diào)度三大技術(shù)突破破解端側(cè)AI“三堵墻”,配套的Compass AI軟件平臺(tái)則通過(guò)全鏈路工具鏈與開(kāi)放生態(tài)構(gòu)建軟硬件協(xié)同體系,顯著降低大模型端側(cè)部署門(mén)檻。在安謀科技“AI Arm CHINA”戰(zhàn)略下,“周易”NPU與“星辰”CPU等自研IP形成的產(chǎn)品矩陣,以Arm生態(tài)為基礎(chǔ)、本土創(chuàng)新為核心推動(dòng)產(chǎn)業(yè)融合,為終端提供高效AI支撐的同時(shí),加速端側(cè)AI規(guī)模化商用。



